Im letzten Jahr hat sich der Bot-Traffic von etwas, das Website-Betreiber ignorieren konnten, zu etwas entwickelt, die das Verhalten der Infrastruktur direkt beeinflusst. Bei dieser Veränderung geht es nicht nur um das Volumen. Es geht darum, wie automatisierter Traffic mit modernen Websites interagiert, insbesondere mit WooCommerce-Shops.
Oberflächlich betrachtet mag es so aussehen, als sei eine Anfrage einfach nur eine Anfrage. Aber nicht alle Anfragen sind gleich, und WooCommerce macht diesen Unterschied noch deutlicher.
In diesem Artikel erfährst du, warum WooCommerce-Websites empfindlicher auf Bot-Traffic reagieren, was unter der Haube passiert, wenn Bots auf wichtige Endpunkte treffen, und warum gängige Annahmen über Traffic und Leistung im E-Commerce-Kontext nicht zutreffen.
Warum WooCommerce Traffic in Arbeitslast verwandelt
Bei einer typischen WordPress-Website werden die meisten Seiten in einem CDN wie Cloudflare zwischengespeichert, so dass die Anfragen ohne Einschaltung des ursprünglichen Servers ausgeliefert werden. Selbst bei höherem Volumen bleiben die Kosten relativ niedrig, weil das System für die Wiederverwendung der zwischengespeicherten Ausgabe optimiert ist.
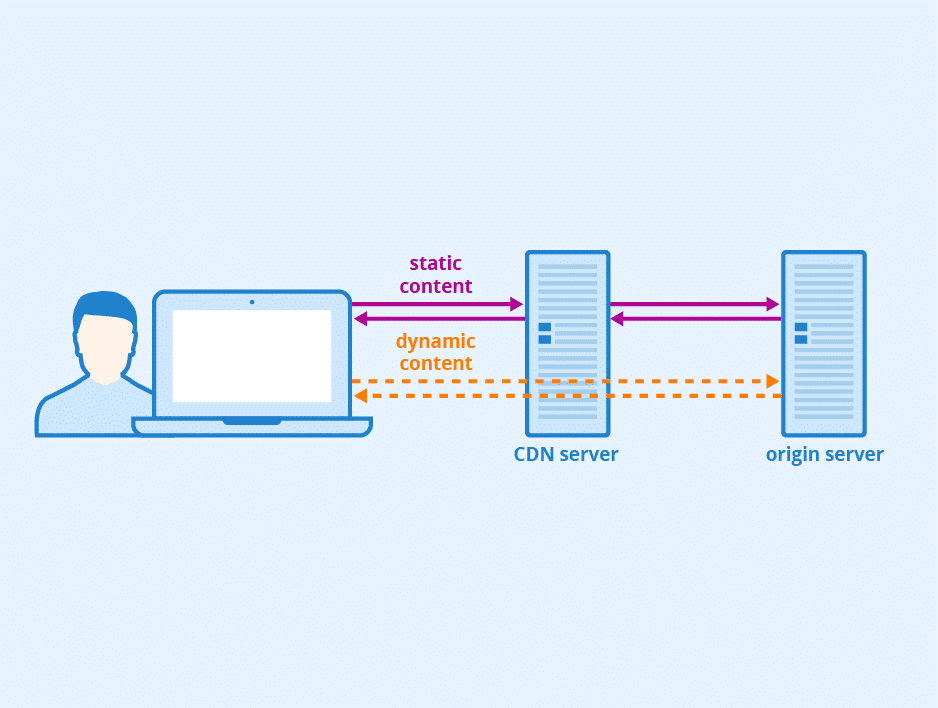
WooCommerce funktioniert anders. Ein großer Teil der Anfragen hängt von Echtzeitdaten und nutzerspezifischem Kontext ab und kann nicht aus dem Cache bedient werden. Jede Anfrage muss auf dem Ursprungsserver von Grund auf bearbeitet werden. Das schließt ein:
- Ausführen von PHP, um die Anfragelogik zu verarbeiten
- Abfrage der Datenbank nach Produkt-, Preis- oder Sitzungsdaten
- Dynamische Erstellung der Antwort, bevor sie zurückgeschickt wird
Die Ausführung von PHP für jede Anfrage belegt einen PHP-Thread für die Dauer des Prozesses, und die Anzahl der für jede Website verfügbaren Threads ist begrenzt. Wenn alle Threads belegt sind, müssen neue Anfragen warten. Möglicherweise stößt deine Website immer wieder an das PHP-Thread-Limit.
Gleichzeitig wird die Datenbank nach Daten und Sitzungsinformationen abgefragt. Auch die Sitzungsverarbeitung findet im Hintergrund statt.
Selbst wenn man das Bot-Verhalten nicht berücksichtigt, ist klar, dass WooCommerce-Anfragen von Natur aus teuer sind. Sobald automatisierter Datentraffic ins Spiel kommt, steigen diese Kosten noch weiter an.
Wo Bots auf WooCommerce-Websites den größten Schaden anrichten
Die Auswirkungen des Bot-Traffics auf WooCommerce-Websites konzentrieren sich in der Regel auf einige wenige Endpunkte, die für die Interaktion mit echten Nutzern gedacht sind.
Dies sind die Bereiche der Website, in denen die Anfragen am teuersten und am wenigsten cachefähig sind:
- Warenkorb- und Kassen-Endpunkte (
/cart,/checkout,?add-to-cart=) - Suchanfragen
- Gefilterte und parameterbasierte Produktseiten
- AJAX-gesteuerte Interaktionen und dynamische Komponenten
Jeder dieser Punkte verhält sich anders, aber jede Anfrage löst eine echte Verarbeitung auf dem Server aus.
Warenkorb- und Checkout-Endpunkte sind die offensichtlichsten Beispiele. Eine Anfrage an /cart oder eine Anfrage mit ?add-to-cart= löst Anwendungslogik aus, um die Sitzung zu validieren, den Status des Warenkorbs zu aktualisieren, Produktdaten abzufragen und eine bestimmte Antwort vorzubereiten. Wenn dies wiederholt und in großem Umfang geschieht, verbraucht es schnell Serverressourcen.
In unserem kürzlich veröffentlichten Bericht „The AI & bot traffic reality check“ hat unser Entwicklungsteam herausgefunden, dass innerhalb von 24 Stunden über sieben Millionen Bot-Anfragen auf add-to-cart-URLs in der Kinsta-Infrastruktur eingingen.
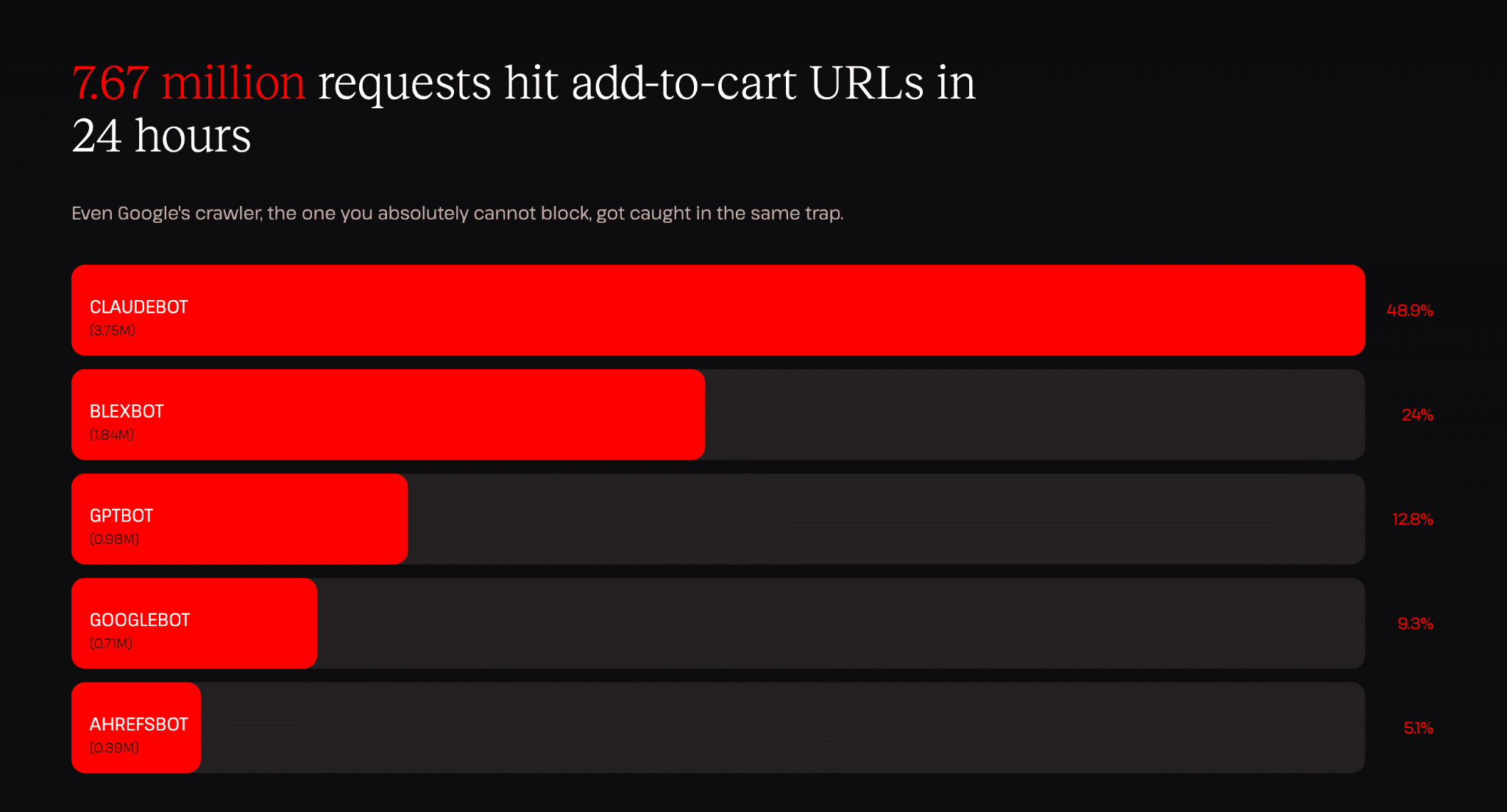
Um die Zahlen ins rechte Licht zu rücken: 3,75 Millionen Anfragen in 24 Stunden von ClaudeBot sind ungefähr eine Anfrage alle 23 Millisekunden (den ganzen Tag und die ganze Nacht), wobei jede Anfrage als eine neue Anfrage behandelt wird.
Abgesehen von den Endpunkten für den Warenkorb und die Kasse stellen auch die Suche und das Filtern eine andere Art von Druck dar. In WooCommerce-Geschäften können die Nutzer/innen die Produkte oft nach Attributen wie Preis, Kategorie, Größe oder Verfügbarkeit filtern. Jede Kombination erzeugt eine etwas andere URL, und aus der Sicht eines Crawlers ist jede Variante eine Erkundung wert.
In unserem Bericht stellten wir fest, dass der Meta-Externalagent (Facebook/Meta AI Crawler) tagelang auf WooCommerce-Vergleichswebsites feststeckte und sich in sinnlose Variationen auf Kalenderseiten verstrickte.
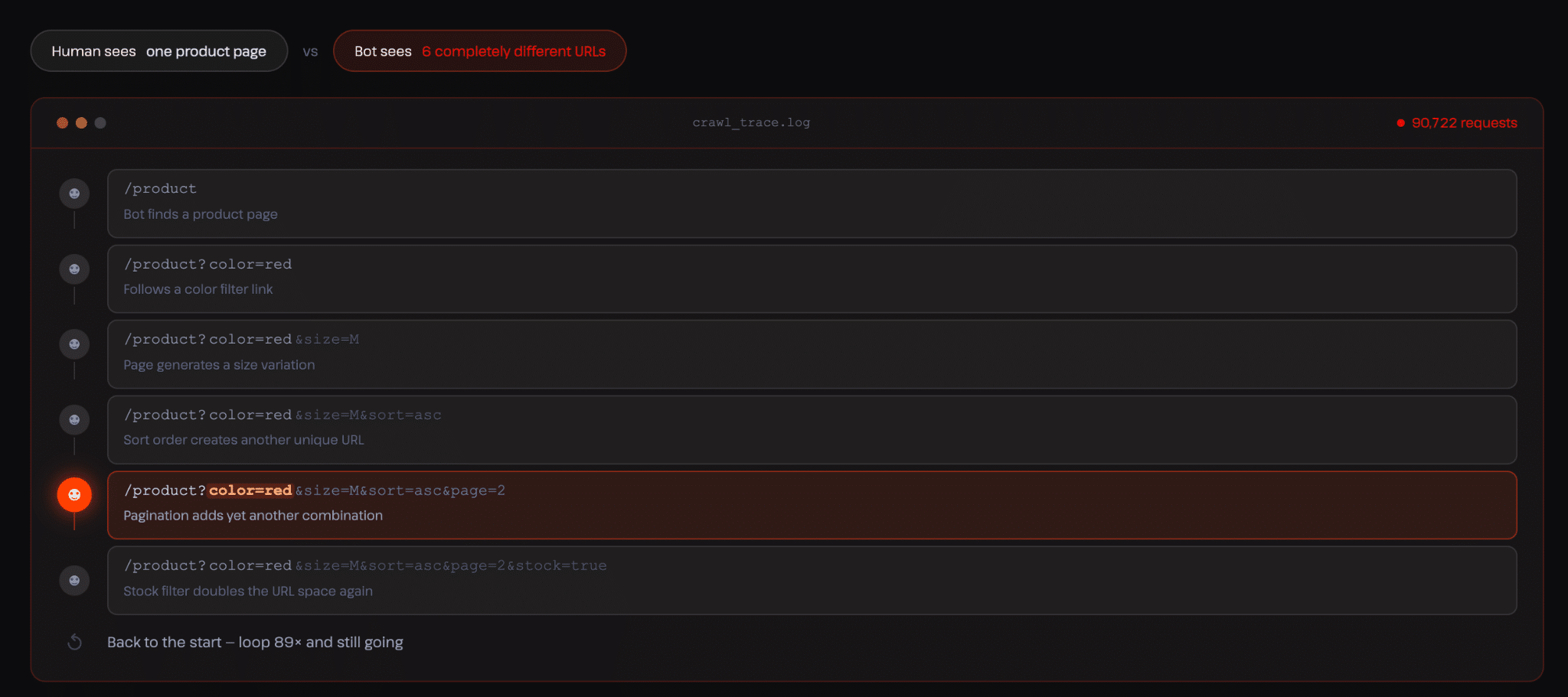
Das passiert, weil Crawler den Kontext nicht verstehen. Der Crawler folgt der ersten Variante, entdeckt dann eine andere, leicht abweichende Version, dann noch eine, und erweitert seinen Pfad immer weiter. Er erkennt zu keinem Zeitpunkt, dass er eigentlich immer wieder dieselbe Seite besucht.
Auf WooCommerce-Websites ist das besonders problematisch, weil viele dieser Variationen mit dynamischen Funktionen verbunden sind.
Warum Bot-Traffic nicht wie ein Angriff aussieht (aber sich wie einer verhält)
Ein Grund, warum dieses Problem leicht zu übersehen ist, liegt darin, dass es nicht wie ein bösartiger Angriff aussieht.
Bei einem böswilligen Angriff bemerkst du Spitzen aus einer einzigen Quelle mit eindeutigen Anzeichen von Missbrauch und möglicherweise böswilligen Nutzdaten, aber bei Bot-Traffic sehen die Anfragen normal aus, weil sie der Struktur der Website folgen, auf gültige URLs zugreifen und gültige Antworten erhalten.
Von außen betrachtet sieht es oft wie legitime Crawling-Aktivitäten aus, aber das System bewertet nicht die Absicht. Es verarbeitet nur die Anfragen.
Wenn ineffiziente oder schlecht funktionierende Crawler in großem Umfang arbeiten, erzeugen sie Muster, die einem Missbrauch ähneln, auch wenn das nicht das ursprüngliche Ziel war. Wiederholte Anfragen, Schleifen und der häufige Zugriff auf dynamische Endpunkte führen zu einer anhaltenden Arbeitsbelastung des Servers.
Aus diesem Grund ist die Unterscheidung zwischen „guten“ und „schlechten“ Bots in der Praxis weniger sinnvoll.
Ein Crawler kann legitim sein und trotzdem Traffic-Muster erzeugen, die die Leistung beeinträchtigen. Es geht nicht nur darum, wer die Anfrage stellt, sondern auch darum, wozu diese Anfrage das System zwingt.
Was das für die Leistung von WooCommerce bedeutet
Wenn diese Art von Datentraffic zunimmt, zeigen sich die Auswirkungen auf eine Weise, die leicht falsch zugeordnet werden kann.
- Die Seiten werden langsamer geladen, besonders in Spitzenzeiten
- Der Checkout-Fluss ist verzögert oder inkonsistent
- In manchen Fällen stauen sich die Anfragen, weil die PHP-Threads mit der Bearbeitung wiederholter automatisierter Interaktionen beschäftigt sind
Von außen betrachtet sieht es wie ein Leistungsproblem aus, aber die eigentliche Ursache ist oft der anhaltende Druck durch automatisierten Traffic, der auf nicht gecachte Endpunkte trifft.
Dies wirkt sich auch darauf aus, wie der Datentraffic interpretiert wird. Große Mengen automatisierter Anfragen können die Zahl der Besuche in die Höhe treiben, ohne dass dies mit der tatsächlichen Nutzeraktivität zusammenhängt. Eine Spitze im Traffic entspricht nicht unbedingt einem Anstieg des Engagements, der Konversionen oder des Umsatzes. Ohne Einblick in die Ursachen des Traffics ist es schwierig, die tatsächliche Nachfrage von der automatisierten Last zu unterscheiden.
Im großen Maßstab wird dies sowohl zu einem Leistungs- als auch zu einem Entscheidungsproblem.
Warum das Blockieren von Bots keine vollständige Lösung ist
Wenn du dich noch nicht mit dem Bot-Traffic auskennst, ist deine natürliche Reaktion auf diese Art von Verhalten, ihn zu blockieren. In manchen Fällen funktioniert das auch. Aber in den meisten Fällen entstehen dadurch neue Kompromisse.
Die Wahrheit ist, dass nicht jeder automatisierte Traffic schädlich ist. Suchmaschinen-Crawler sind wichtig für die Sichtbarkeit. KI-Crawler spielen eine Rolle dabei, wie Inhalte über KI-Agenten auftauchen, was heute als GEO- und AEO-Verfahren bezeichnet wird.
Alles zu blockieren beseitigt das Trafficproblem, aber es beseitigt auch die Vorteile. Wenn du alles zulässt, vermeidest du zwar Störungen, aber du setzt das System unnötiger Belastung aus.
Die Herausforderung besteht darin, dass WooCommerce-Websites nicht eine einzige Regel für den gesamten Datentraffic benötigen. Sie brauchen ein unterschiedliches Verhalten, je nachdem, wohin die Anfrage geht und woher der Traffic kommt.
Eine praktischere Art, über Bot-Traffic nachzudenken
Anstatt zu fragen, ob Bots zugelassen oder blockiert werden sollten, ist die sinnvollere Frage: Welche Arten von Traffic sollten auf welche Teile der Website zugreifen dürfen?
Auf Einkaufswagen- und Checkout-Endpunkte müssen Crawler gar nicht zugreifen können. Die Suche und die gefilterten Seiten können eingeschränkt werden, ohne dass die Kernfunktionalität beeinträchtigt wird. Gleichzeitig müssen die Produkt- und Kategorieseiten für Suchmaschinen zugänglich bleiben.
Durch diese Art der Trennung wird der Bot-Traffic beherrschbar.
Unsere Analyse von mehr als 10 Milliarden Anfragen über die von Kinsta verwaltete Infrastruktur zeigt, dass diese Muster auf echten WooCommerce-Websites immer wieder auftreten. Wenn du den gesamten Datensatz untersuchen und sehen möchtest, wie sich diese Muster über verschiedene Website-Typen hinweg entwickeln, findest du im KI-Bot-Traffic-Bericht weitere Details.
Gleichzeitig ist die manuelle Verwaltung dieser Daten kaum praktikabel. Es erfordert von Zeit zu Zeit Anpassungen, einen klaren Einblick in die Traffic-Muster und eine Möglichkeit, Entscheidungen zu treffen, ohne die legitime Nutzung zu unterbrechen. Genau diese Lücke soll das Bot-Schutz-Tool von Kinsta schließen, indem es Website-Betreibern die Möglichkeit gibt, den Umgang mit verschiedenen Arten von Traffic zu steuern, ohne sich auf pauschale Regeln zu verlassen.
Sieh dir unsere Dokumente an und kontaktiere den Support, wenn du mehr darüber wissen möchtest, wie das für deine Website oder Agentur funktionieren kann.

Joel ist Frontend-Entwickler und arbeitet bei Kinsta als Technical Editor. Er ist ein leidenschaftlicher Lehrer mit einer Vorliebe für Open Source und hat über 200 technische Artikel geschrieben, die sich hauptsächlich um JavaScript und seine Frameworks drehen.